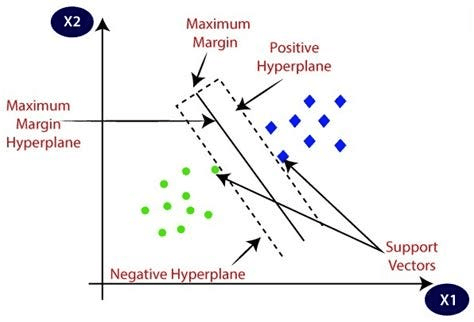
Support Vector
# Tag:
- Source/KU_ML2
Support Vector
이 instance와 decision boundary 사이의 거리를 margin이라고 하며, 이를 최대화 하는 것을 SVM이라고 한다.
- Decision Boundary: HyperPlane(초평면). n차원에 그려진 초평면(n-1 차원)이, desicion boundary가 된다.
- : HyperPlane of 3 dim.
- Hyperplane : a surface generated by a straight line moving at a constant velocity. 2차원이라면, 3차원으로 그어진 HyperPlane이라 할 수 있다.
Optimal Seperating hyperplane
이 0보다 큰 지, 작은 지에 따라 class를 이진 분류한다.
decision boundary 위의 점 에 대해서, 이 된다.
의 크기 로 나누어, 를 단위 벡터로 취급하여 생각할 때, 이다.
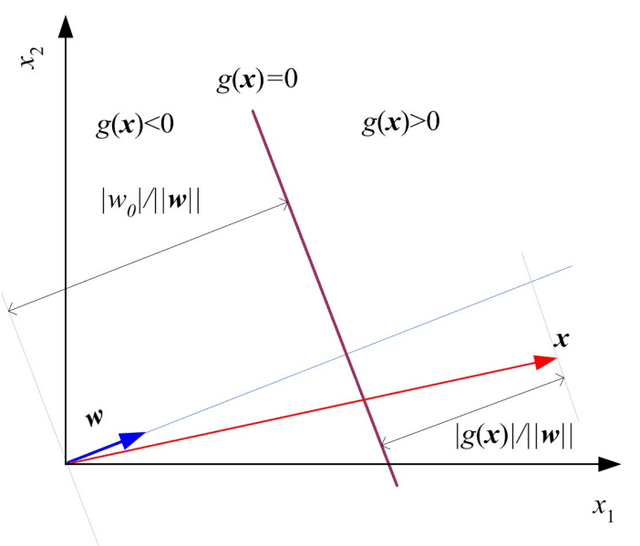
그렇다면, 에 대하여, 해당 instance를 어떤 class인지 분류하는 것은 decision boundary에서 얼마나 떨어져 있는지, distance를 측정하는 것으로 바꿀 수 있다.
이 0보다 큰 지, 작은 지에 따라 class가 분류된다.
이 원점에서 decision boundary까지의 거리가 되므로 decision boundary의 우측에 있으면 거리가 0보다 클 것이고, 좌측에 있으면 거리가 0보다 작게 될 것이다.
을 뺀다는 것은, 단위 벡터 에 를 곱한 것에, 이 decision boundary 위에 있으므로 decision boundary 까지의 거리를 잰다는 것과 동일해진다.
이러한 idea를 바탕으로 distance를 기반으로 분류하는 문제로 전환할 수 있다.
Margin으로의 전환
이 때, optimal hyperplane은 margin이 가장 최대화 되는 hyperplane이다.
- train data의 instance에 noise가 약간 낀 형태로 test data가 주어질 것이라는 믿음이 일반적이다. 따라서, train data에 noise가 껴서 decision boundary에 가까워져도 margin이 커야 잘 분류 가능할 것이다.
- Nonparametric Methods처럼, 비슷한 값끼리는 모여 있을 것이니 최대한 margin을 크게 해야 비슷한 값끼리 잘 모여있는 것을 예측할 수 있을 것이다.
- 비슷한 input은, 보통 비슷한 output끼리 모여 있다.
label 를 편의를 위해 라고 하자.
위에서 정의된 에 따르면, 가 0보다 작을 때는 negative, 0보다 클때는 positive이다. 이를 margin의 정의에 따르게 하려면
가 되도록 해야 한다. 즉, decision boundary까지의 거리가 모든 instance에 대해 margin 보다 커야 한다.
Maxinum Margin HyperPlane
로 바꾸어 문제를 전환하자.
로 고정되게 정의하자면, 가 가장 커지게 하는 를 찾는 문제가 된다. 실제로 의 크기가 중요한 것이 아니라 그 방향이 중요하므로 해당 방식이 성립한다. 상수를 곱해도 optimization은 성립하기 때문이다.
: when 이라는 constaints가 있는 optimization problem(Quadratic Programming)이 된다.
즉, 가 작아지면 가 커지고, 적절한 방향으로 고정되는 constaints를 가진 optimization이 된다.
As Primal Problem
: 는 Lagrange Multiplier이다.
이에 대해
이다. 은 constaints를 위한 조건이다.
constaints: 에 대하여,
- constrains < 0 : 가 무한에 가까워 질 수록 가 성립한다. 이는, 해당 instance가 제약 조건이 성립하지 않으므로, margin 안에 존재하여 margin에 직접적인 영향을 미치는 경우이다. 즉, margin을 결정하는데 영향을 주도록 가 커지도록 한다.
- constrains 0: 일 때, 가 성립한다. 이는, 해당 instance가 제약 조건이 성립해 margin 밖에 존재함을 의미한다. 이 되도록 해, decision boundary 결정에 배제되도록 한다.
As Dual Problem
는 데이터의 feature 수와 같으므로 차원이 높을 경우 계산량이 급격히 증가한다. 따라서 Dual Problem으로 전환해 SVM에서 kernel trick을 위한 계산을 효율적이게 한다.
내적만 계산하면 되고, 보통 데이터의 샘플 수는 차원보다 작은 경우가 많아 compuation cost가 상당히 감소하게 된다.
Primal Problem의 Lagrangier function에, optimal 문제를 풀어 나온 결과를 대입하면
내적에 대한, 의 개수에 dependent한 문제로 바뀐다.
이 때, KKT Condition이 된다.
- : 둘 중 하나는 0
마찬가지로, Quadratic Programming 혹은 Gradient Descent(여기서는 gradient ascent, maximizing 해야 하므로)로 조건을 풀 수 있다.
Support Vector
모든 instance를 이용하지 않고 Support vector만을 이용해 optimal한 hyperplane을 결정할 수 있는 것이다.
Support Vector Subset을 라 하고, 위의 조건대로 풀면
- :
- :
그리고, 이므로 이고,
과 같이 optimal decision boundary를 결정 할 수 있다.